Cloud Data Fusion in Google Cloud Platform is a fully managed, cloud-native data integration service.
Table of Contents
Definition:
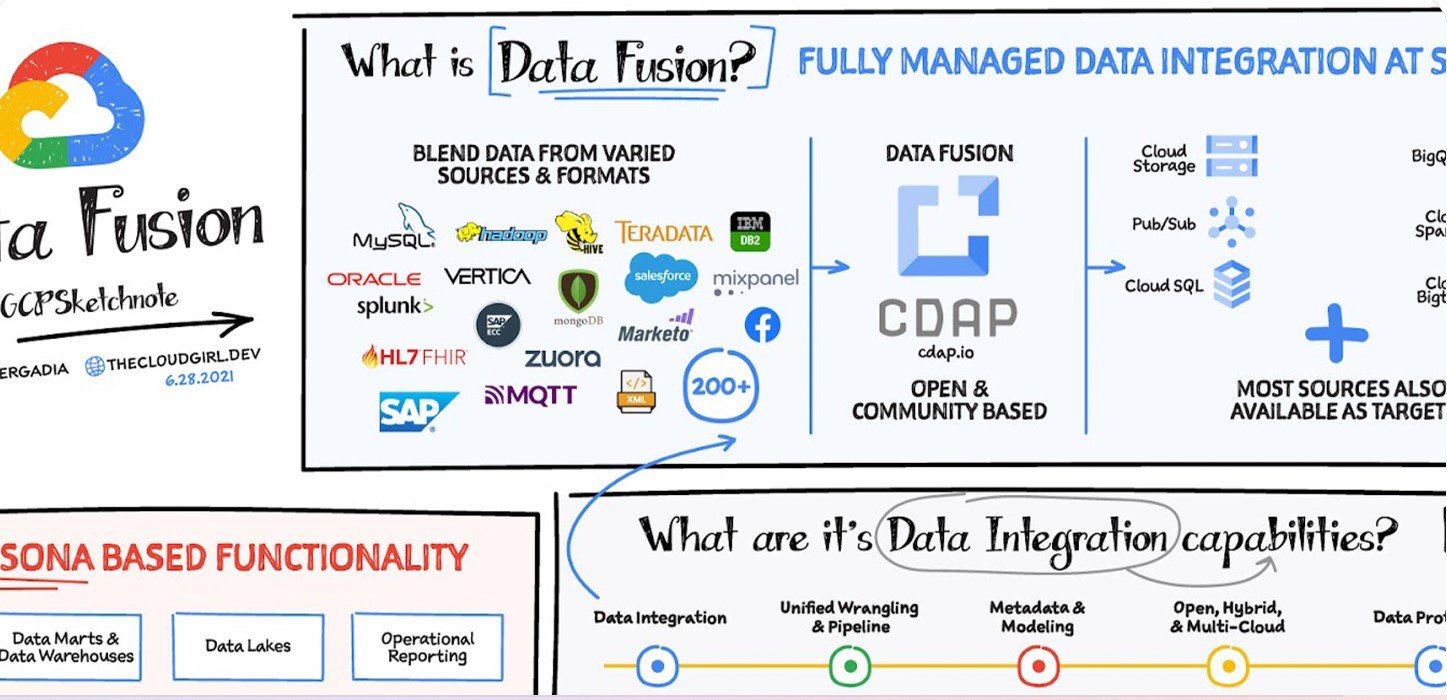
Google Cloud Data Fusion is a managed service that simplifies the process of integrating, transforming, and enriching data from various sources. It provides a visual interface for designing data pipelines, eliminating the need for manual coding. Data Fusion is built on the open-source project CDAP (Cask Data Application Platform) and supports a wide range of data sources, transformations, and sinks.
How to use:
1. Set up a Data Fusion instance: Create a new Data Fusion instance in the GCP Console. Choose the instance type (Basic or Enterprise) and select a region where the instance will be deployed.
2. Access the Data Fusion UI: Once the instance is running, you can access the Data Fusion UI from the GCP Console.
3. Explore data sources: Connect to data sources such as Cloud Storage, BigQuery, or databases by configuring the appropriate connectors in Data Fusion.
4. Design pipelines: Use the visual interface to create data pipelines by dragging and dropping sources, transformations, and sinks onto the canvas. Configure each stage by defining the required properties and schema.
5. Deploy and run pipelines: Deploy the pipelines to run on Dataproc clusters. Monitor the execution, view logs, and track the progress of your pipelines using the Data Fusion UI or Stackdriver Logging and Monitoring.
Commands:
Cloud Data Fusion does not have specific command-line tool support, as it is primarily designed for use through its visual UI. However, you can manage Data Fusion instances using the `gcloud` command-line tool:
– To create an instance: `gcloud beta data-fusion instances create INSTANCE_NAME –location LOCATION –type TYPE`
– To list instances: `gcloud beta data-fusion instances list –location LOCATION`
– To delete an instance: `gcloud beta data-fusion instances delete INSTANCE_NAME –location LOCATION`
Use cases:
– Data integration from various sources into a data warehouse or data lake
– Data preparation and transformation for analytics, reporting, and machine learning
– Data migration and synchronization across systems
– Data enrichment by joining and aggregating data from multiple sources